1The Hong Kong University of Science and Technology, Hong Kong SAR
2Ocean University of China, China
3CFAR & IHPC, A*STAR, Singapore
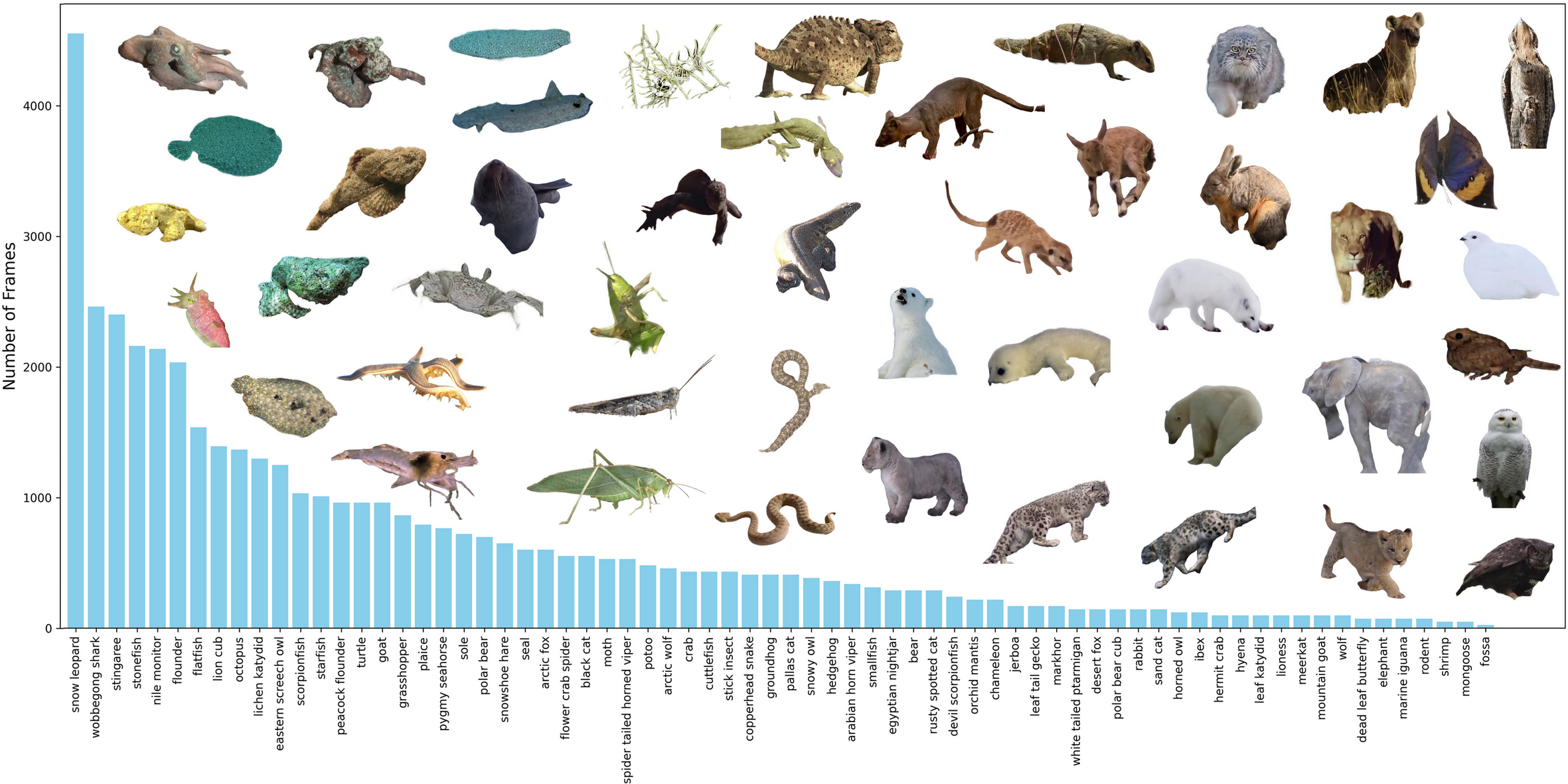
Category distribution and some visual examples (extracted animal masks) of our dataset.
Abstract
We have been witnessing remarkable success led by the power of neural networks driven by a significant scale of
training data in handling various computer vision tasks.
However, less attention has been paid to monitoring the camouflaged animals, the masters of hiding themselves in
the background.
Performing robust and precise camouflaged animal segmentation is not trivial even for domain experts because of
their consistent appearance with backgrounds.
Even though several efforts were made to perform camouflaged animal image segmentation, there is only some work
on camouflaged animal video segmentation to the best of the author's knowledge.
Biologists usually favor videos with redundant information and temporal consistencies to perform biological
monitoring and understanding of the behavior and events of animals.
The scarcity of such labeled video data is the most hindering issue.
To address these challenges, we present CamoVid60K, a diverse, large-scale, and accurately annotated
video dataset of camouflaged animals.
This dataset comprises 218 videos with 62,774 finely annotated frames, covering 70 animal
categories, which surpasses all previous datasets in terms of the number of videos/frames and species included.
CamoVid60K also offers more diverse downstream tasks in CV, such as camouflaged animal classification,
detection, and task-specific segmentation (semantic, referring, motion), etc.
We have benchmarked several state-of-the-art algorithms on the proposed CamoVid60K dataset, and the
experimental results provide valuable insights into future research directions.
Our dataset stands as a novel and challenging testing set to stimulate more powerful camouflaged animal video
segmentation algorithms, and there is still a large room for further improvement.
Camouflage is a powerful biological mechanism for avoiding detection and identification. In nature,
camouflage tactics are employed to deceive the sensory and cognitive processes of both preys and predators.
Wild animals utilize these tactics in various ways, ranging from blending themselves into the surrounding
environment to employing disruptive patterns and colouration. Identifying camouflage is pivotal in many
wildlife surveillance applications, as it assists in locating hidden individuals for study and protection.
Concealed scene understanding (CSU) is a hot computer vision topic aiming to learn discriminative features
that can be used to discern camouflaged target objects from their surroundings. The MoCA dataset is the most
extensive compilation of videos featuring camouflaged objects, yet it only provides detection labels.
Consequently, researchers often evaluate the efficacy of sophisticated segmentation models by transforming
segmentation masks into detection bounding boxes. With the recent advent of MoCA-Mask, there’s been a shift
towards video segmentation in concealed scenes. However, despite these advancements, the data annotations
remain insufficient in both volume and accuracy for developing a reliable video model capable of effectively
handling complex concealed situations. The below table compares our proposed dataset with previous ones,
showing that CamoVid60K surpasses all previous datasets in terms of the number of videos/frames and species
included.
Comparison with existing video animal datasets. Class.: Classification Label, B.Box:
Bounding Box, Motion: Motion of Animal, Coarse OF: Coarse Optical Flow, Expres.: Expression.
Note that, MVK dataset mostly consists of normal marine animals with only some
camouflaged animals. The frequency of annotations refers to how often each frame is annotated. For instance,
MoCA-Mask provides annotations for every five frames, resulting in 4,691 annotated frames. In contrast, our
CamoVid60K dataset offers a significantly larger volume of data with more frequent annotations and a wider
variety of annotation types.
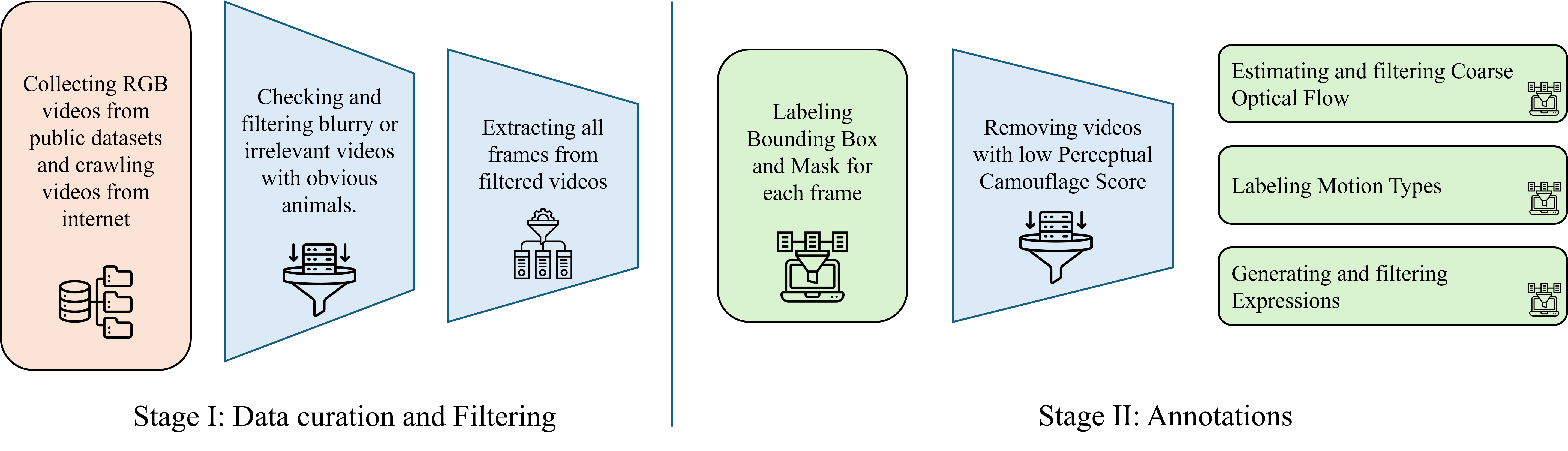
CamoVid60K data pipeline. Stage I includes data curation, filtering irrelevant videos,
and
extracting all frames. Stage II includes data annotation, generation, and filtering.
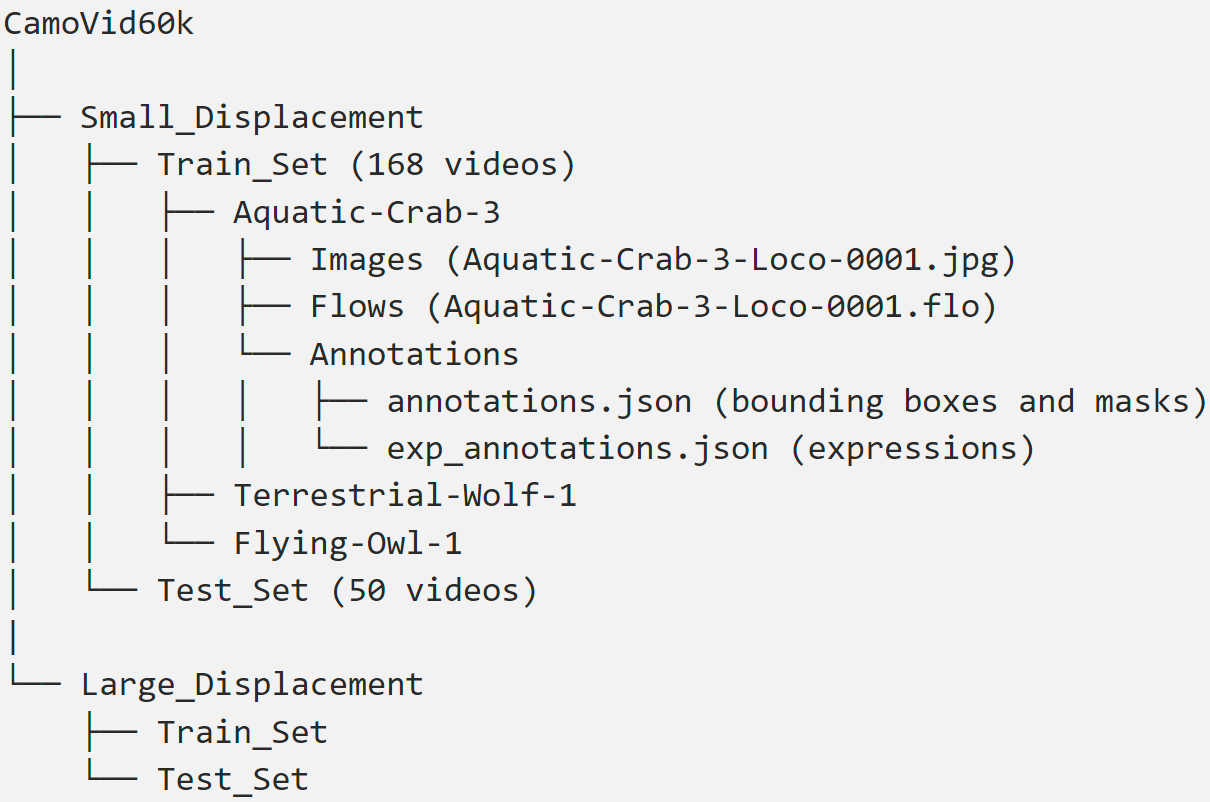
Data organization of our dataset.
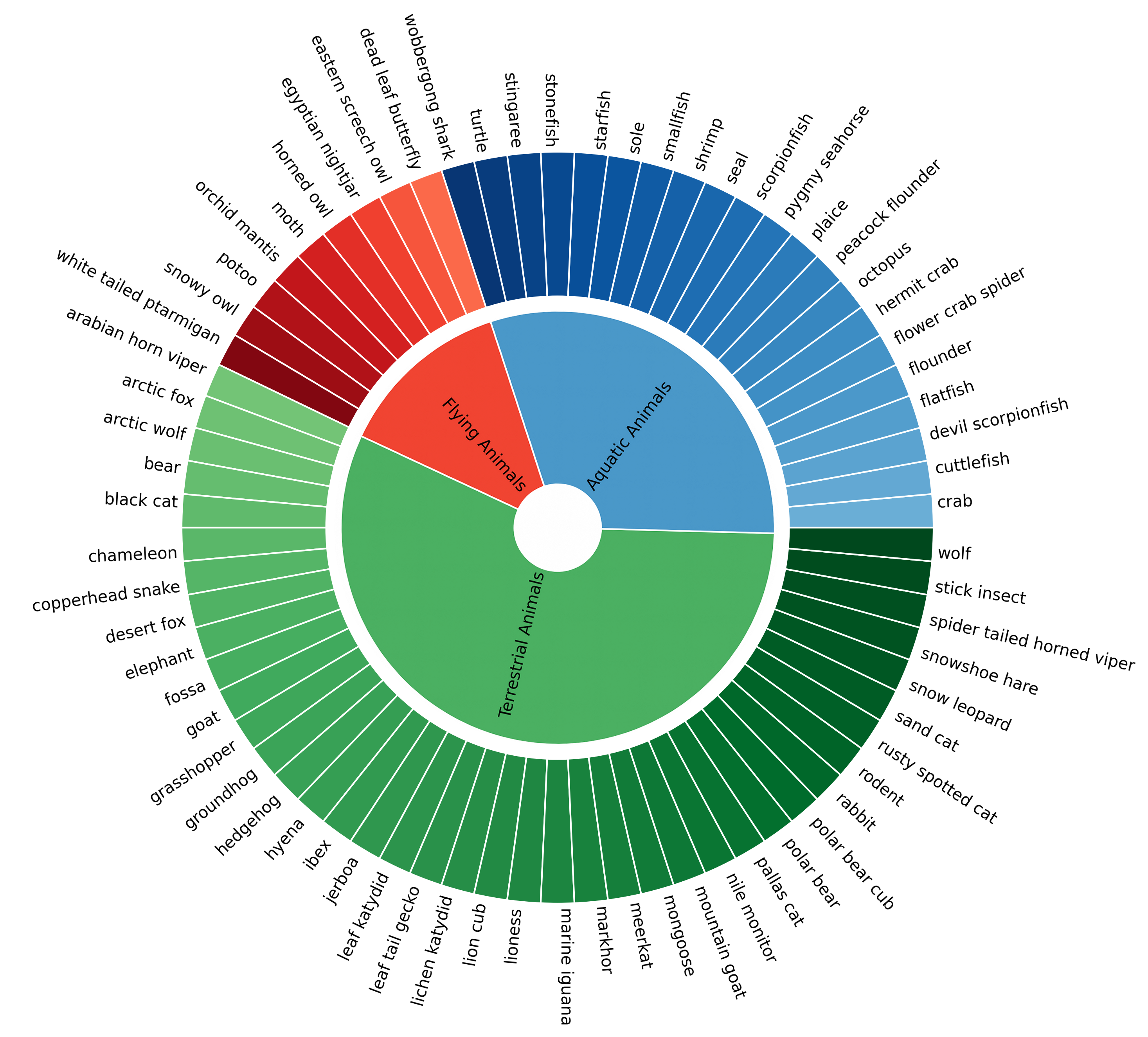
Word cloud of category distribution of camouflaged animals.
This work is supported by an internal grant from HKUST (R9429). This work is partially done when Tuan-Anh Vu was
a research resident at CFAR & IHPC, A*STAR, Singapore. The website is modified from this template.
 CamoVid60K: A Large-Scale Video Dataset for Moving Camouflaged Animals Understanding
CamoVid60K: A Large-Scale Video Dataset for Moving Camouflaged Animals Understanding